![]()
Benchmarking: retrieving and comparing against reference results#
You can access all the latest results for classification, clustering and regression directly with aeon. These results are all stored on the website
timeseriesclassification.com. These results were presented in three bake offs for classification [1], regression [2] and clustering [3]. We use three aeon classifiers for our examples.
FreshPRINCE [4] is a pipeline of TSFresh transform followed by a rotation forest classifier. InceptionTimeClassifier [5] is a deep learning ensemble. HIVECOTEV2 [6] is a meta ensemble of four different ensembles built on different representations. WEASEL2 [7] overhauls original WEASEL using dilation and ensembling randomized hyper-parameter settings.
See [1] for an overview of recent advances in time series classification.
[1]:
from aeon.benchmarking import plot_critical_difference
from aeon.benchmarking.results_loaders import (
get_estimator_results,
get_estimator_results_as_array,
)
from aeon.benchmarking.results_plotting import plot_boxplot_median, plot_scatter
classifiers = [
"FreshPRINCEClassifier",
"HIVECOTEV2",
"InceptionTimeClassifier",
"WEASEL-Dilation",
]
datasets = ["ACSF1", "ArrowHead", "GunPoint", "ItalyPowerDemand"]
# get results. To read locally, set the path variable.
# If you do not set path, results are loaded from
# https://timeseriesclassification.com/results/ReferenceResults.
# You can download the files directly from there
default_split_all, data_names = get_estimator_results_as_array(estimators=classifiers)
print(
" Returns an array with each column an estimator, shape (data_names, classifiers)"
)
print(
f"By default recovers the default test split results for {len(data_names)} "
f"equal length UCR datasets."
)
default_split_some, names = get_estimator_results_as_array(
estimators=classifiers, datasets=datasets
)
print(
f"Or specify datasets for result recovery. For example, {len(names)} datasets. "
f"HIVECOTEV2 accuracy {names[3]} = {default_split_some[3][1]}"
)
Returns an array with each column an estimator, shape (data_names, classifiers)
By default recovers the default test split results for 112 equal length UCR datasets.
Or specify datasets for result recovery. For example, 4 datasets. HIVECOTEV2 accuracy ItalyPowerDemand = 0.9698736637512148
If you have any questions about these results or the datasets, please raise an issue on the associated repo. You can also recover results in a dictionary, where each key is a classifier name, and the values is a dictionary of problems/results.
[2]:
hash_table = get_estimator_results(estimators=classifiers)
print("Keys = ", hash_table.keys())
print(
"Accuracy of HIVECOTEV2 on ItalyPowerDemand = ",
hash_table["HIVECOTEV2"]["ItalyPowerDemand"],
)
Keys = dict_keys(['FreshPRINCEClassifier', 'HIVECOTEV2', 'InceptionTimeClassifier', 'WEASEL-Dilation'])
Accuracy of HIVECOTEV2 on ItalyPowerDemand = 0.9698736637512148
The results recovered so far have all been on the default train/test split. If we merge train and test data and resample, you can get very different results. To allow for this, we average results over 30 resamples. You can recover these averages by setting the default_only parameter to False.
[3]:
resamples_all, data_names = get_estimator_results_as_array(
estimators=classifiers, default_only=False
)
print("Results are averaged over 30 stratified resamples.")
print(
f" HIVECOTEV2 default train test partition of {data_names[3]} = "
f"{default_split_all[3][1]} and averaged over 30 resamples = "
f"{resamples_all[3][1]}"
)
Results are averaged over 30 stratified resamples.
HIVECOTEV2 default train test partition of ECG200 = 0.87 and averaged over 30 resamples = 0.8866666666666667
So once you have the results you want, you can compare classifiers with built in aeon tools. For example, you can draw a critical difference diagram [7]. This displays the average rank of each estimator over all datasets. It then groups estimators for which there is no significant difference in rank into cliques, shown with a solid bar. So in the example below with the default train test splits, FreshPRINCEClassifier and WEASEL-Dilation are not significantly different in ranks to InceptionTimeClassifier, but HIVECOTEV2 is significantly better. The diagram below has been performed using pairwise Wilcoxon signed-rank tests and forms cliques using the Holm correction for multiple testing as described in [8, 9]. Alpha value is 0.05 (default value).
[8]:
plot = plot_critical_difference(default_split_all, classifiers, clique_method="holm")
plot.show()
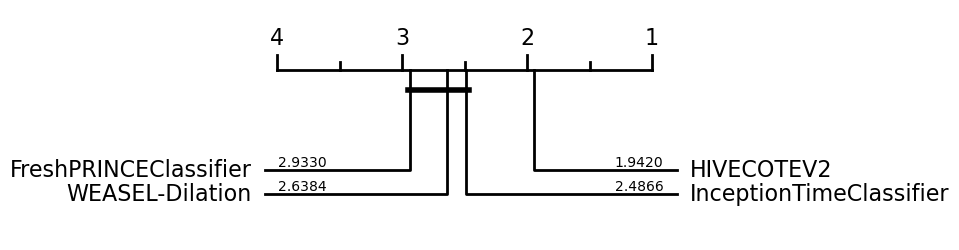
If we use the data averaged over resamples, we can detect differences more clearly. Now we see WEASEL-Dilation and InceptionTimeClassifier are significantly better than the FreshPRINCEClassifier.
[9]:
plot = plot_critical_difference(resamples_all, classifiers, clique_method="holm")
plot.show()
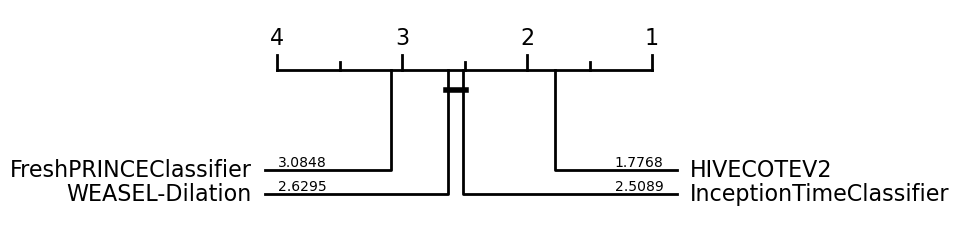
If we want to highlight a specific classifier, we have the highlight parameter, which is a dict including the classifier that we would like to highlight and the colour selected, such as: highlight={HIVECOTEV2: "#8a9bf8"}
[15]:
plot = plot_critical_difference(
resamples_all,
classifiers,
clique_method="holm",
highlight={"HIVECOTEV2": "#8a9bf8"},
)
plot.show()
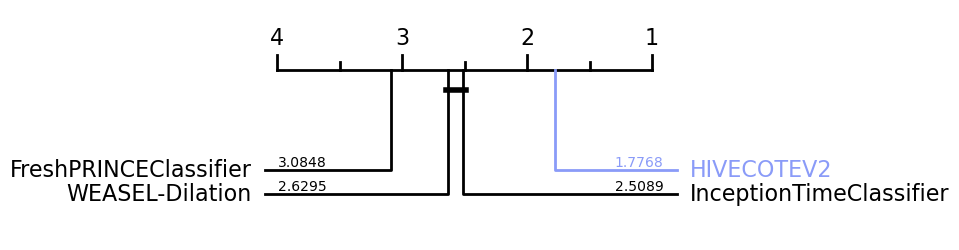
Besides plotting differences using the critical difference diagrams, different versions of boxplots can be plotted. Boxplots graphically demonstrates the locality, spread and skewness of the results. In this case, it plot a boxplot of distributions from the median. A value above 0.5 means the algorithm is better than the median accuracy for that particular problem.
[10]:
plot = plot_boxplot_median(
resamples_all,
classifiers,
plot_type="boxplot",
outliers=True,
)
plot.show()
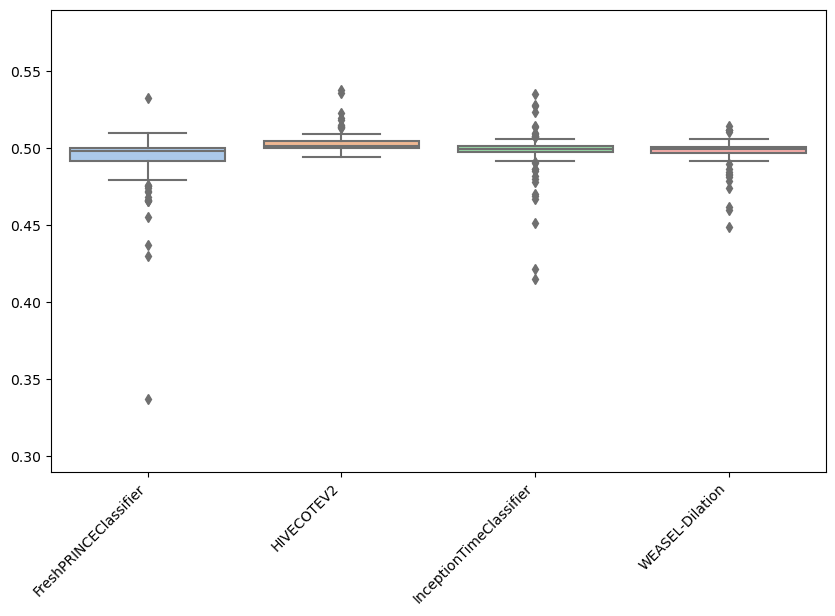
As can be observed, the results achieved by the FreshPRINCEClassifier are more spreaded than the rest. Furthermore, it can be seen that most results for HC2 are above 0.5, which indicates that for most datasets, HC2 is better.
There are some more options to play with in this function. For example, to specify the values for the y-axis:
[13]:
plot = plot_boxplot_median(
resamples_all,
classifiers,
plot_type="boxplot",
outliers=True,
y_min=0.4,
y_max=0.6,
)
plot.show()
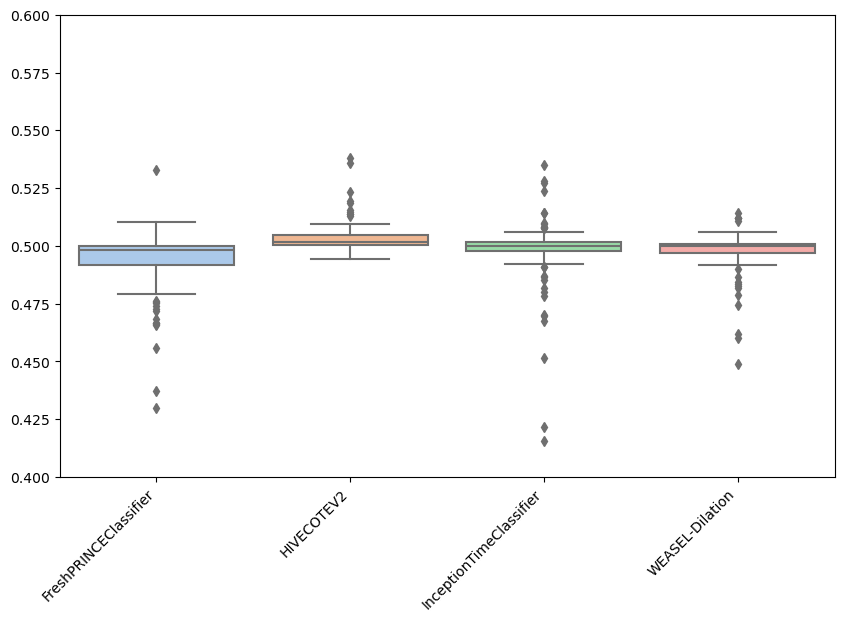
Apart from well-known boxplots, different versions can be plotted, depending on the purpose of the user: - violin is a hybrid of a boxplot and a kernel density plot, showing peaks in the data. - swarm is a scatterplot with points adjusted to be non-overlapping. - strip is similar to swarm but uses jitter to reduce overplotting.
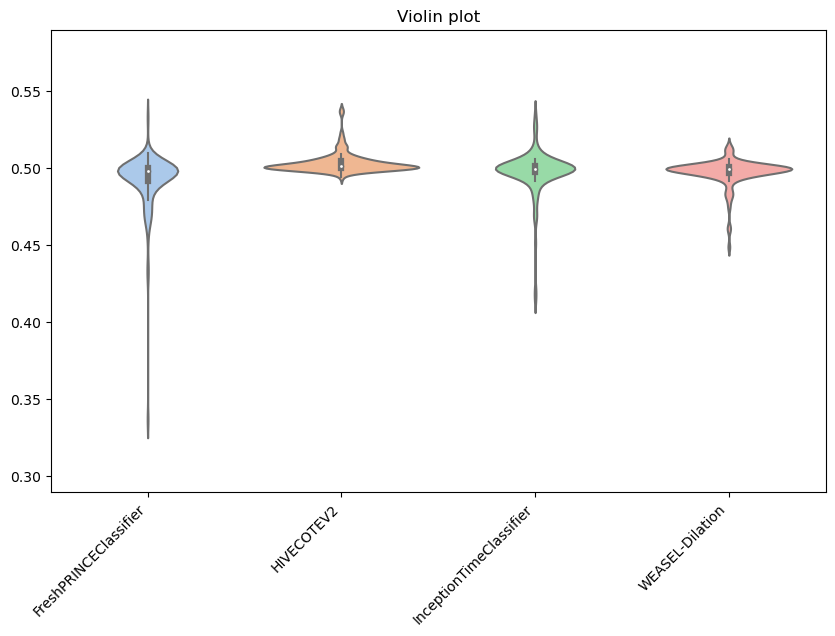
Below, we show an example of the violin one, including a title.
[14]:
plot = plot_boxplot_median(
resamples_all,
classifiers,
plot_type="violin",
title="Violin plot",
)
plot.show()
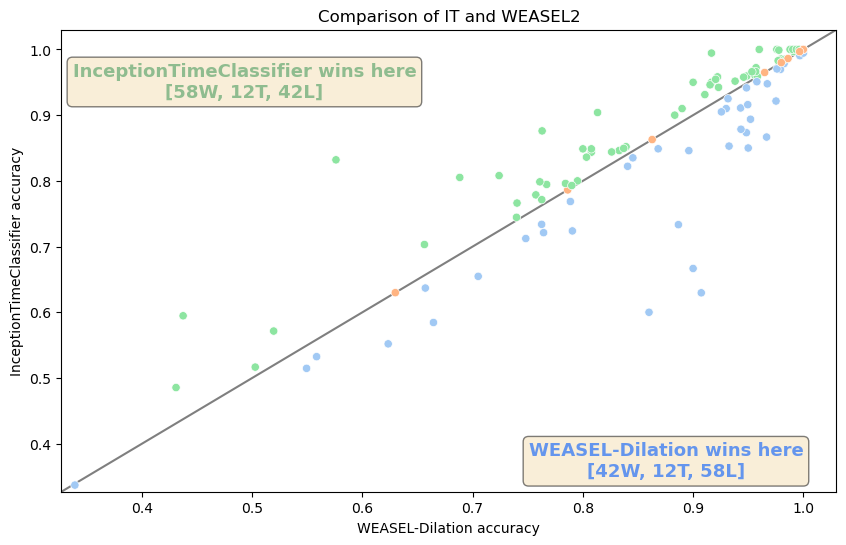
From the critical difference diagram above, we showed that InceptionTimeClassifier is not significantly better than WEASEL-Dilation. Now, if we want to specifically compare the results of these two approaches, we can plot a scatter in which each point is a pair of accuracies of both approaches. The number of W, T, and L is also included per approach in the legend.
[21]:
methods = ["InceptionTimeClassifier", "WEASEL-Dilation"]
results = get_estimator_results_as_array(estimators=methods)
plot = plot_scatter(
results[0],
methods[0],
methods[1],
title="Comparison of IT and WEASEL2",
)
plot.show()
timeseriesclassification.com has results for classification, clustering and regression. We are constantly updating the results as we generate them. To find out which estimators have results get_available_estimators
[15]:
from aeon.benchmarking import get_available_estimators
print(get_available_estimators(task="Classification"))
print(get_available_estimators(task="Regression"))
print(get_available_estimators(task="Clustering"))
classification
0 FreshPRINCE
1 HC2
2 Hydra-MR
3 InceptionT
4 PF
5 RDST
6 RSTSF
7 WEASEL_D
regression
0 FreshPRINCE
clustering
0 KMeans
References#
[1] Middlehurst et al. “Bake off redux: a review and experimental evaluation of recent time series classification algorithms”, 2023, arXiv
[2] Holder et al. “A Review and Evaluation of Elastic Distance Functions for Time Series Clustering”, 2023, arXiv KAIS
[3] Guijo-Rubio et al. “Unsupervised Feature Based Algorithms for Time Series Extrinsic Regression”, 2023 arXiv
[4] Middlehurst and Bagnall, “The FreshPRINCE: A Simple Transformation Based Pipeline Time Series Classifier”, 2022 arXiv
[5] Fawaz et al. “InceptionTime: Finding AlexNet for time series classification”, 2020 DAMI
[6] Middlehurst et al. “HIVE-COTE 2.0: a new meta ensemble for time series classification”, MACH
[7] Schäfer and Leser, “WEASEL 2.0 - A Random Dilated Dictionary Transform for Fast, Accurate and Memory Constrained Time Series Classification”, 2023 arXiv
[8] García and Herrera, “An extension on ‘statistical comparisons of classifiers over multiple data sets’ for all pairwise comparisons”, 2008 JMLR
[9] Benavoli et al. “Should We Really Use Post-Hoc Tests Based on Mean-Ranks?”, 2016 JMLR
[10] Demsar, “Statistical Comparisons of Classifiers over Multiple Data Sets” JMLR
Generated using nbsphinx. The Jupyter notebook can be found here.