![]()
Time series clustering¶
Time series clustering (TSCL) is a hugely popular research field that has engendered thousands of publications. The core problem is to group together Broadly, TSCL can be grouped into those that work with (possibly transformed) whole time series, and those that derive features that are not time dependent, and then use a standard clustering algorithm.
This graph summarises the different approaches
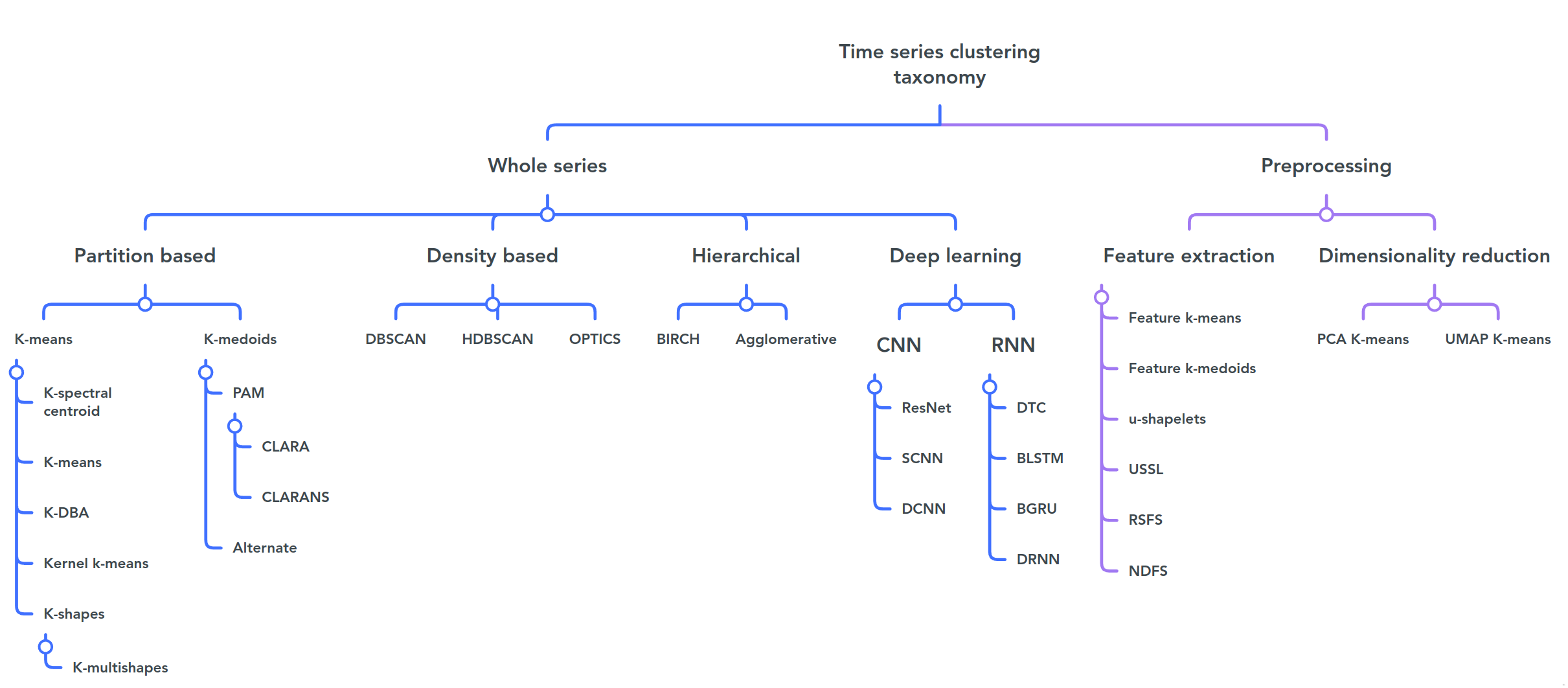
Fig. 1. A taxonomy of time series clustering algorithms, taken from [1]. The following models are included: K-means [2], K-spectral centroid [3], K-DBA [4], Kernel K-means [5], K- shapes [6], K-multishapes [7], PAM [8], CLARA [9], CLARANS [10], Al- ternate [11], DBSCAN [12], HDBSCAN[13], OPTICS [14], BIRCH [15], Agglom- erative [16], Feature K-means [17], Feature K-medoids [17], U-shapelets [18], USSL [19], RSFS [20], NDFS [21], Deep learning and dimensionality reduction approaches see [22]
Clustering notebooks¶
aeoncurrently focusses on partition based approaches that use elastic distance functions. The partition based note book has an overview of the funtionality in aeon.sklearnhas density based and hierarchical based clustering algorithms, and these can be used in conjunction withaeonelastic distances. See the sklearn and aeon distances notebook.Deep learning based TSCL is a very popular topic, and we are working on bringing deep learning functionality to
aeon, first algorithms for [Deep learning] are COMING SOONBespoke feature based TSCL algorithms are easily constructed with
aeontransformers andsklearnclusterers in a pipeline. Some examples are in the [sklearn clustering]. We will bring the bespoke feature based clustering algorithms intoaeonin the medium term.
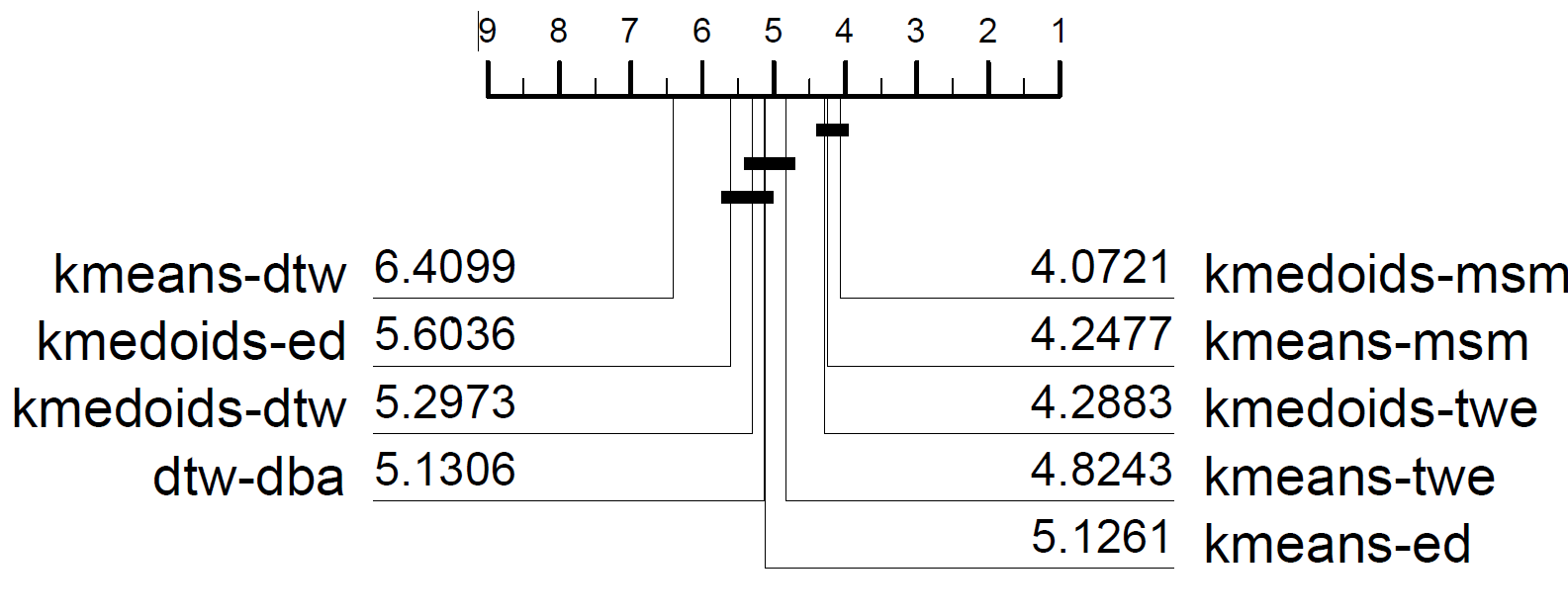
We are in the process of extending the bake off described in [1] to include all clusterers. So far, we find medoids with MSM distance is the best performer.
References¶
[1] Christopher Holder, Matthew Middlehurst, and Anthony Bagnall. A Review and Evaluation of Elastic Distance Functions for Time Series Clustering, Knowledge and Information Systems. In Press (2023)
[2] J. MacQueen et al. Some methods for classification and analysis of multivariate observations. In Proceedings of the fifth Berkeley symposium on mathematical statistics and probability, volume 1, pages 281–297, 1967
[3] J. Yang and J. Leskovec. Patterns of temporal variation in online media. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, WSDM’11, page 177–186, 2011.
[4] F. Petitjean, A. Ketterlin, and P. Gancarski. A global averaging method for dynamic time warping, with applications to clustering. Pattern Recognition, 44:678–, 03 2011
[5] I. S. Dhillon, Y. Guan, and B. Kulis. Kernel k-means: Spectral clustering and normalized cuts. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2004
[6] J. Paparrizos and L. Gravano. k-shape: Efficient and accurate clustering of time series. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, pages 1855–1870, 2015
[7] J. Paparrizos and L. Gravano. Fast and accurate time-series clustering. ACM Transactions on Database Systems (TODS), 42(2):1–49, 2017
[8] P. J. R. Leonard Kaufman. Partitioning Around Medoids (Program PAM), chapter 2, pages 68–125. John Wiley and Sons, Ltd, 1990
[9] L. Kaufman and P. J. Rousseeuw. Clustering large data sets. In Pattern Recognition in Practice, pages 425–437, 1986
[10] R. Ng and J. Han. CLARANS: A method for clustering objects for spatial data mining. Knowledge and Data Engineering, IEEE Transactions on, 14:1003– 1016, 10 2002
[11] S. P. Lloyd. Least squares quantization in pcm. IEEE Trans. Inf. Theory, 28:129–136, 1982
[12] M. Ester, H.-P. Kriegel, J. Sander, and X. Xu. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, page 226–231, 1996
[13] L. McInnes and J. Healy. Accelerated hierarchical density based clustering. IEEE International Conference on Data Mining Workshops (ICDMW), pages 33–42, 2017
[14] M. Ankerst, M. M. Breunig, H.-P. Kriegel, and J. Sander. Optics: Ordering points to identify the clustering structure. SIGMOD Rec., 28(2):49–60, 1999
[15] T. Zhang, R. Ramakrishnan, and M. Livny. Birch: An efficient data clustering method for very large databases. SIGMOD Rec., 25(2):103–114, June 1996
[16] J. H. W. Jr. Hierarchical grouping to optimize an objective function. Journal of the American Statistical Association, 58(301):236–244, 1963
[17] T. R ̈as ̈anen and M. Kolehmainen. Feature-based clustering for electricity use time series data. volume 5495, 2009
[18] J. Zakaria, A. Mueen, and E. Keogh. Clustering time series using unsupervised- shapelets. In 2012 IEEE 12th International Conference on Data Mining, pages 785–794, 2012
[19] Q. Zhang, J. Wu, P. Zhang, G. Long, and C. Zhang. Salient subsequence learning for time series clustering. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 41(9):2193–2207, 2019
[20] L. Shi, L. Du, and Y.-D. Shen. Robust spectral learning for unsupervised feature selection. In 2014 IEEE International Conference on Data Mining, pages 977–982, 2014
[21] Z. Li, Y. Yang, J. Liu, X. Zhou, and H. Lu. Unsupervised feature selection using nonnegative spectral analysis. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, AAAI’12, page 1026–1032. AAAI Press, 2012
[22] B. Lafabregue, J. Weber, P. Gancarski, and G. Forestier. End-to-end deep representation learning for time series clustering: a comparative study. Data Mining and Knowledge Discovery, 36:29—-81, 2022
Generated using nbsphinx. The Jupyter notebook can be found here.