![]()
Distance based time series classification in aeon#
Distance based classifiers use a time series specific distance function to measure the similarity between time series. Time series distance functions are often called elastic distances, since they compensate for possible misalignment between series by shifting or editing the series.
Dynamic time warping is the best known elastic distance measure. This image demonstrates how a warping path is found between two series 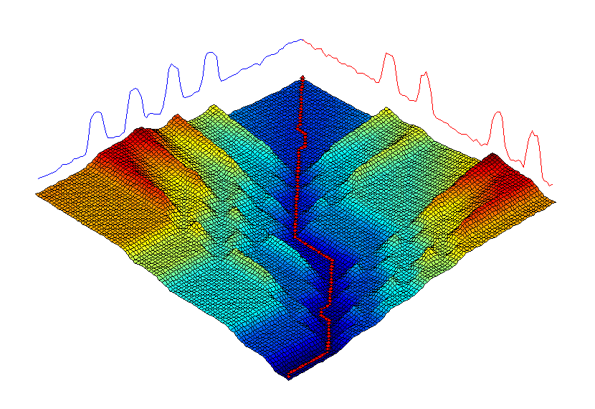
We have a range of elastic distance functions in the distances module. Please see the distance notebook for more information. Distance functions have been mostly used with a nearest neighbour (NN) classifier, but you can use them with sklearn and aeon distances
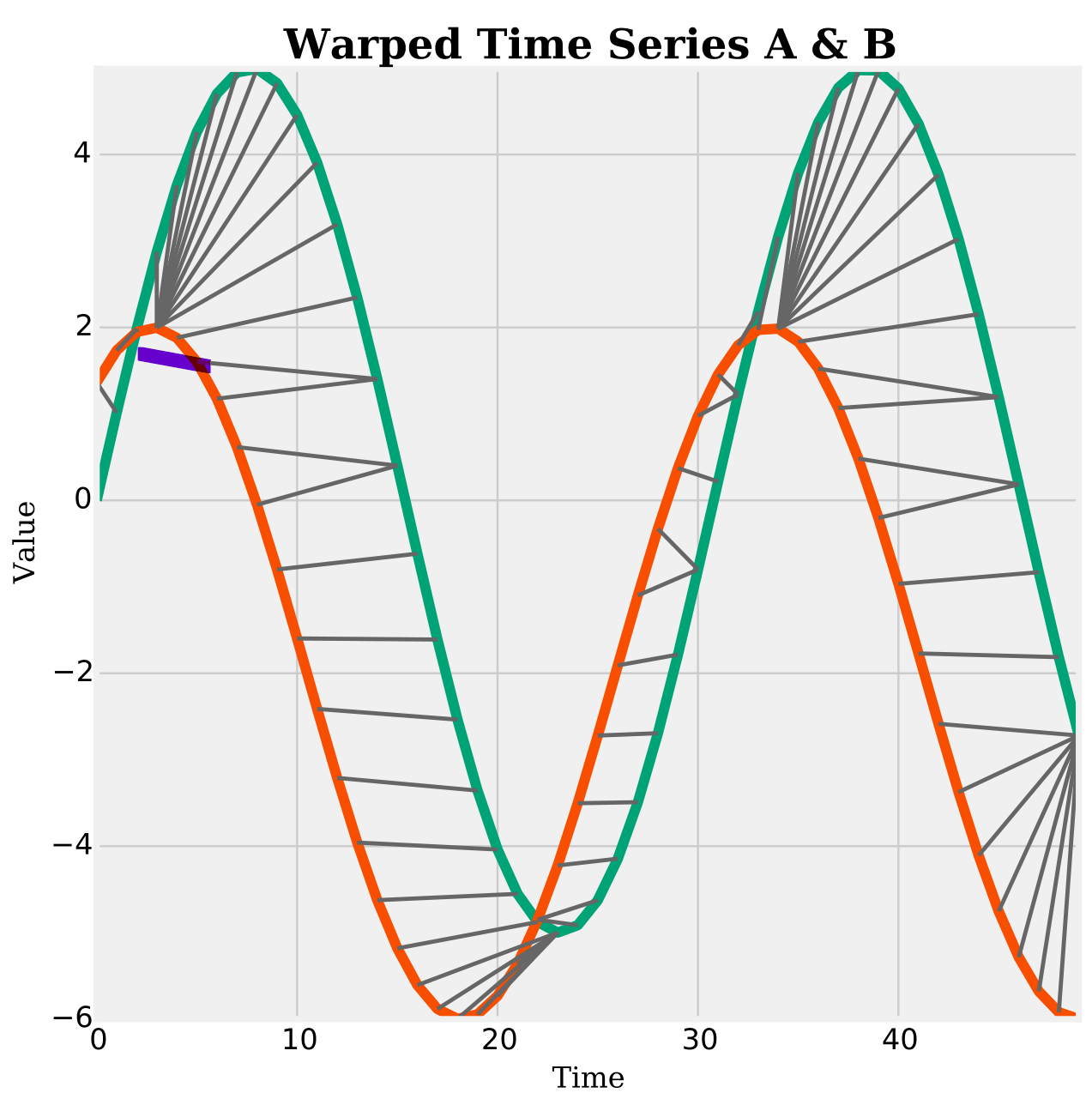
- alignment.
- width:
400
- class:
no-scaled-link
Load data and list distance based classifiers#
[5]:
import warnings
from sklearn import metrics
from aeon.datasets import load_italy_power_demand
from aeon.registry import all_estimators
warnings.filterwarnings("ignore")
all_estimators("classifier", filter_tags={"algorithm_type": "distance"})
[5]:
[('ElasticEnsemble',
aeon.classification.distance_based._elastic_ensemble.ElasticEnsemble),
('KNeighborsTimeSeriesClassifier',
aeon.classification.distance_based._time_series_neighbors.KNeighborsTimeSeriesClassifier),
('MatrixProfileClassifier',
aeon.classification.feature_based._matrix_profile_classifier.MatrixProfileClassifier),
('ShapeDTW', aeon.classification.distance_based._shape_dtw.ShapeDTW)]
Distance based classifiers#
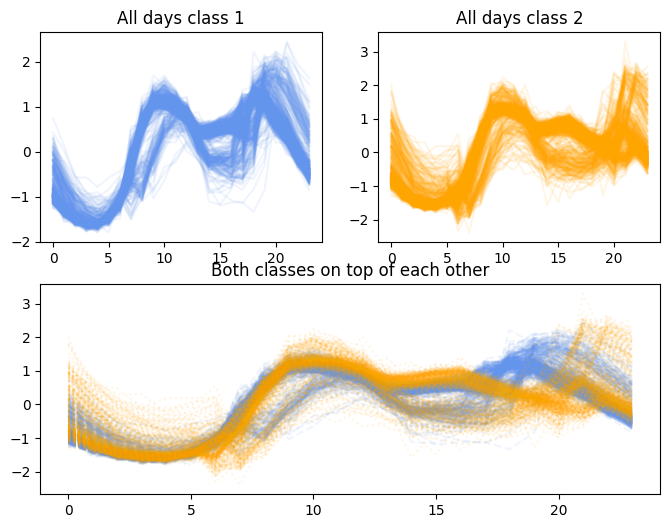
The data was derived from twelve monthly electrical power demand time series from Italy and first used in the paper “Intelligent Icons: Integrating Lite-Weight Data Mining and Visualization into GUI Operating Systems”. The classification task is to distinguish days from Oct to March (inclusive) from April to September.
The dataset consists of 1096 rows in total. Each row represents a day of Italys electric power consumption. All days have a label either 1 or 2. 67 rows are used for training and the rest are for testing.
[21]:
X_train, y_train = load_italy_power_demand(split="train", return_X_y=True)
X_test, y_test = load_italy_power_demand(split="test", return_X_y=True)
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
(67, 1, 24) (67,) (1029, 1, 24) (1029,)
[26]:
import matplotlib.pyplot as plt
import numpy as np
fig, axs = plt.subplots(2, 2, figsize=(8, 6))
axs[1, 1].axis("off")
axs[1, 0].axis("off")
ax_combined = fig.add_subplot(2, 1, (2, 3))
axs[0, 0].set_title("All days class 1")
axs[0, 1].set_title("All days class 2")
ax_combined.set_title("Both classes on top of each other")
for i in np.where(y_test == "1")[0]:
axs[0, 0].plot(X_test[i][0], alpha=0.1, color="cornflowerblue", linestyle="solid")
ax_combined.plot(X_test[i][0], alpha=0.1, color="cornflowerblue", linestyle="--")
for i in np.where(y_test == "2")[0]:
axs[0, 1].plot(X_test[i][0], alpha=0.1, color="orange", linestyle="solid")
ax_combined.plot(X_test[i][0], alpha=0.1, color="orange", linestyle=":")
[22]:
from aeon.classification.distance_based import (
ElasticEnsemble,
KNeighborsTimeSeriesClassifier,
ShapeDTW,
)
K-NN: KNeighborsTimeSeriesClassifier in aeon#
k-NN is often called a lazy classifier, because there is little work done in the fit operation. The fit operation simply stores the training data. When we want to make a prediction for a new time series, k-NN measures the distance between the new time series and all the series in the training data and records the class of the closest k train series. The class labels of these nearest neighbours are used to make a prediction: if they are all the same label, then that is the prediction. If they differ, then some form of voting mechanism is required. For example, we may predict the most common class label amongst the nearest neighbours for the test instance.
KNeighborsTimeSeriesClassifier in aeon is configurable to use any of the distances functions in the distance module, or it can be passed a bespoke callable. You can set the number of neighbours and the weights. Weights are used in the prediction process when neightbours differ in class values. By default all neighbours have an equal vote. There is an option to weight by distance, meaning closer neighbours have more weight in the vote.
[23]:
knn = KNeighborsTimeSeriesClassifier(distance="msm", n_neighbors=3, weights="distance")
knn.fit(X_train, y_train)
knn_preds = knn.predict(X_test)
metrics.accuracy_score(y_test, knn_preds)
[23]:
0.9572400388726919
Elastic Ensemble: ElasticEnsemble in aeon#
The first algorithm to significantly out perform 1-NN DTW on the UCR data was the Elastic Ensemble (EE) [1]. EE is a weighted ensemble of 11 1-NN classifiers with a range of elastic distance measures. It was the best performing distance based classifier in the bake off. Elastic distances can be slow, and EE requires cross validation to find the weights of each classifier in the ensemble. You can configure EE to use specified distance functions, and tell it how much.
[24]:
ee = ElasticEnsemble(
distance_measures=["dtw", "msm"],
proportion_of_param_options=0.1,
proportion_train_in_param_finding=0.3,
proportion_train_for_test=0.5,
)
ee.fit(X_train, y_train)
ee_preds = ee.predict(X_test)
metrics.accuracy_score(y_test, ee_preds)
[24]:
0.9552964042759962
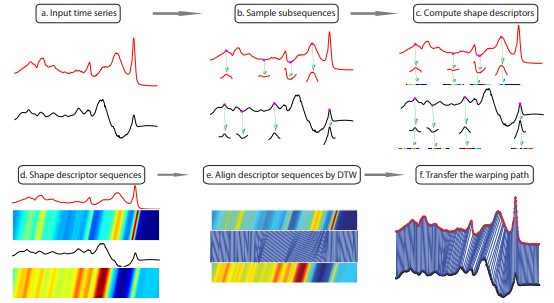
Shape Dynamic Time Warping: ShapeDTW in aeon.#
Shape based DTW (ShapeDTW) [2] works by extracting a set of shape descriptors (such as slope and derivative) over windows of each series. These series to series transformed data are then used with 1-NN with DTW.
[25]:
shape = ShapeDTW()
shape.fit(X_train, y_train)
shape_preds = shape.predict(X_test)
metrics.accuracy_score(y_test, shape_preds)
[25]:
0.9650145772594753
Proximity Forest#
Proximity Forest [3] is a distance based ensemble of decision trees. Its is the most accurate purely distance based technique for TSC that we know of. We do not currently have a working version of PF in aeon, but would very much like to have one. please see this issue. https://github.com/aeon-toolkit/aeon/issues/159
Comparing performance: coming soon#
References#
[1] Lines J, Bagnall A (2015) Time series classification with ensembles of elastic distance measures. Data Mining and Knowledge Discovery 29:565–592 [2] Zhao J. and Itti L (2019) shapeDTW: Shape Dynamic Time Warping, Pattern Recognition 74:171-184 https://arxiv.org/pdf/1606.01601.pdf [3] Lucas et al. (2019) Proximity Forest: an effective and scalable distance-based classifier. Data Mining and Knowledge Discovery 33: 607–635 https://arxiv.org/abs/1808.10594
Generated using nbsphinx. The Jupyter notebook can be found here.