![]()
Loading data with unequal length series or missing values¶
Some of the archive datasets have variable length series or missing values. Some algorithms can handle this type of data internally, but many cannot. You can find out estimator capabilities through the tags. For example, the ability to handle unequal length series internally is indicated by the tag capability:unequal_length. You can find out which estimators have this capability by using all_estimators.
[1]:
from aeon.registry import all_estimators
all_estimators(
estimator_types="classifier", filter_tags={"capability:unequal_length": True}
)
[1]:
[('Catch22Classifier',
aeon.classification.feature_based._catch22.Catch22Classifier),
('DummyClassifier', aeon.classification._dummy.DummyClassifier),
('ElasticEnsemble',
aeon.classification.distance_based._elastic_ensemble.ElasticEnsemble),
('KNeighborsTimeSeriesClassifier',
aeon.classification.distance_based._time_series_neighbors.KNeighborsTimeSeriesClassifier),
('MockClassifierFullTags',
aeon.testing.mock_estimators._mock_classifiers.MockClassifierFullTags),
('RDSTClassifier', aeon.classification.shapelet_based._rdst.RDSTClassifier)]
Collections of unequal length series are stored as a list of 2D arrays. There are two unequal length example problems in aeon
[2]:
from aeon.datasets import load_japanese_vowels, load_plaid
j_vowels, j_labels = load_japanese_vowels()
p_vowels, p_labels = load_plaid()
print(type(j_vowels[0].shape), " ", type(p_vowels[0].shape))
print("shape first =", j_vowels[0].shape, "shape 11th =", j_vowels[10].shape)
<class 'tuple'> <class 'tuple'>
shape first = (12, 20) shape 11th = (12, 23)
The TSML archive TSC.com contains several unequal length series, including 11 from the UCR univariate archive and seven from the multivariate archive.
[3]:
from aeon.datasets.tsc_datasets import (
multivariate_unequal_length,
univariate_variable_length,
)
print(univariate_variable_length)
print(multivariate_unequal_length)
{'PickupGestureWiimoteZ', 'GestureMidAirD2', 'ShakeGestureWiimoteZ', 'PLAID', 'GesturePebbleZ1', 'AllGestureWiimoteZ', 'GestureMidAirD1', 'GestureMidAirD3', 'GesturePebbleZ2', 'AllGestureWiimoteY', 'AllGestureWiimoteX'}
{'AsphaltObstaclesCoordinates', 'SpokenArabicDigits', 'InsectWingbeat', 'CharacterTrajectories', 'JapaneseVowels', 'AsphaltPavementTypeCoordinates', 'AsphaltRegularityCoordinates'}
It is commonplace to preprocess variable length series prior to classification/regression/clustering. There are tools to do this in aeon directly. For example, you can pad series to the longest length or you can truncate them to the shortest length series in the collection if unequal length:
[4]:
from aeon.transformations.collection import PaddingTransformer, TruncationTransformer
padder = PaddingTransformer()
truncator = TruncationTransformer()
padded_j_vowels = padder.fit_transform(j_vowels)
truncated_j_vowels = truncator.fit_transform(j_vowels)
print(padded_j_vowels.shape, truncated_j_vowels.shape)
(640, 12, 29) (640, 12, 7)
There is not one best way of dealing with unequal length series. TSC has equal length version of all unequal length datasets and you can load these directly with load_classification and load_regression functions where the equalising operation is bespoke to the problem. For the classification problems, the data was padded with the series mean with low level Gaussian noise added. Loading equal length is the default behaviour
[14]:
from aeon.datasets import load_classification
j_equal, _ = load_classification("JapaneseVowels")
j_unequal, _ = load_classification("JapaneseVowels", load_equal_length=False)
print(type(j_equal))
print(j_equal.shape)
print(type(j_unequal))
<class 'numpy.ndarray'>
(640, 12, 25)
<class 'list'>
This is the case for both the classification and regression problems. When downloaded, it copies a zip file containing both versions.
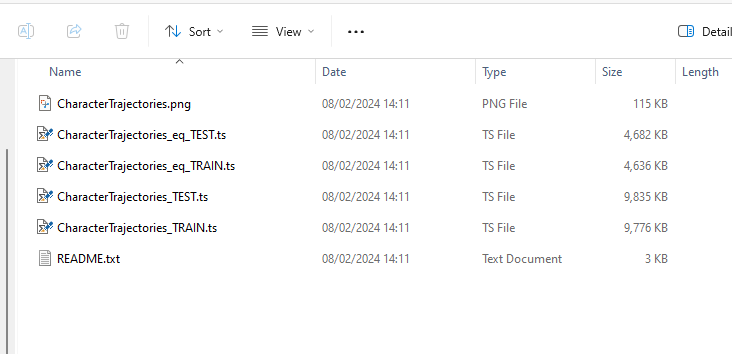
Unequal length problems made equal length have a suffix _eq and those with missing values imputed have suffix _nmv. At the moment we do not have any problems with both missing and unequal length.
[ ]:
Generated using nbsphinx. The Jupyter notebook can be found here.