![]()
Benchmarking time series regression models¶
Time series extrinsic regression, first properly defined in [1] then recently extended in [2], involves predicting a continuous target variable based on a time series. It differs from time series forecasting regression in that the target is not formed from a sliding window, but is some external variable.
This notebook shows you how to use aeon to get benchmarking datasets with aeon and how to compare results on these datasets with those published in [2].
Loading/Downloading data¶
aeon comes with two regression problems in the datasets module. You can load these with single problem loaders or the more general load_regression function.
[14]:
from aeon.datasets import load_cardano_sentiment, load_covid_3month, load_regression
trainX, trainy = load_covid_3month(split="train")
testX, testy = load_regression(split="test", name="Covid3Month")
X, y = load_cardano_sentiment() # Combines train and test splits
print(trainX.shape, testX.shape, X.shape)
(140, 1, 84) (61, 1, 84) (107, 2, 24)
there are currently 63 problems in the TSER archive hosted on timeseriesclassification.com. These are listed in the file datasets.tser_datasets
[15]:
from aeon.datasets.tser_datasets import tser_soton
print(sorted(list(tser_soton)))
['AcousticContaminationMadrid', 'AluminiumConcentration', 'AppliancesEnergy', 'AustraliaRainfall', 'BIDMC32HR', 'BIDMC32RR', 'BIDMC32SpO2', 'BarCrawl6min', 'BeijingIntAirportPM25Quality', 'BeijingPM10Quality', 'BeijingPM25Quality', 'BenzeneConcentration', 'BinanceCoinSentiment', 'BitcoinSentiment', 'BoronConcentration', 'CalciumConcentration', 'CardanoSentiment', 'ChilledWaterPredictor', 'CopperConcentration', 'Covid19Andalusia', 'Covid3Month', 'DailyOilGasPrices', 'DailyTemperatureLatitude', 'DhakaHourlyAirQuality', 'ElectricMotorTemperature', 'ElectricityPredictor', 'EthereumSentiment', 'FloodModeling1', 'FloodModeling2', 'FloodModeling3', 'GasSensorArrayAcetone', 'GasSensorArrayEthanol', 'HotwaterPredictor', 'HouseholdPowerConsumption1', 'HouseholdPowerConsumption2', 'IEEEPPG', 'IronConcentration', 'LPGasMonitoringHomeActivity', 'LiveFuelMoistureContent', 'MadridPM10Quality', 'MagnesiumConcentration', 'ManganeseConcentration', 'MethaneMonitoringHomeActivity', 'MetroInterstateTrafficVolume', 'NaturalGasPricesSentiment', 'NewsHeadlineSentiment', 'NewsTitleSentiment', 'OccupancyDetectionLight', 'PPGDalia', 'ParkingBirmingham', 'PhosphorusConcentration', 'PotassiumConcentration', 'PrecipitationAndalusia', 'SierraNevadaMountainsSnow', 'SodiumConcentration', 'SolarRadiationAndalusia', 'SteamPredictor', 'SulphurConcentration', 'TetuanEnergyConsumption', 'VentilatorPressure', 'WaveDataTension', 'WindTurbinePower', 'ZincConcentration']
You can download these datasets directly with aeon load_regression function. By default it will store the data in a directory called “local_data” in the datasets module. Set extract_path to specify a different location.
[16]:
small_problems = [
"CardanoSentiment",
"Covid3Month",
]
for problem in small_problems:
X, y = load_regression(name=problem)
print(problem, X.shape, y.shape)
CardanoSentiment (107, 2, 24) (107,)
Covid3Month (201, 1, 84) (201,)
This stores the data in a format like this
If you call the function again, it will load from disk rather than downloading again. You can specify train/test splits.
[17]:
for problem in small_problems:
trainX, trainy = load_regression(name=problem, split="train")
print(problem, X.shape, y.shape)
CardanoSentiment (201, 1, 84) (201,)
Covid3Month (201, 1, 84) (201,)
Evaluating a regressor on benchmark data¶
With the data, it is easy to assess an algorithm performance. We will use the DummyRegressor as a baseline, and the default scoring
[18]:
from sklearn.metrics import mean_squared_error
from aeon.regression import DummyRegressor
dummy = DummyRegressor()
performance = []
for problem in small_problems:
trainX, trainy = load_regression(name=problem, split="train")
dummy.fit(trainX, trainy)
testX, testy = load_regression(name=problem, split="test")
predictions = dummy.predict(testX)
mse = mean_squared_error(testy, predictions)
performance.append(mse)
print(problem, " Dummy score = ", mse)
CardanoSentiment Dummy score = 0.09015657223327135
Covid3Month Dummy score = 0.0019998715745554777
Comparing to published results¶
How does the dummy compare to the published results in [2]? We can use the method get_estimator_results to obtain published results.
[19]:
from aeon.benchmarking import get_available_estimators, get_estimator_results
print(get_available_estimators(task="regression"))
results = get_estimator_results(
estimators=["DrCIF", "FreshPRINCE"],
task="regression",
datasets=small_problems,
measure="mse",
)
print(results)
---------------------------------------------------------------------------
SSLCertVerificationError Traceback (most recent call last)
File ~\AppData\Local\Programs\Python\Python39\lib\urllib\request.py:1346, in AbstractHTTPHandler.do_open(self, http_class, req, **http_conn_args)
1345 try:
-> 1346 h.request(req.get_method(), req.selector, req.data, headers,
1347 encode_chunked=req.has_header('Transfer-encoding'))
1348 except OSError as err: # timeout error
File ~\AppData\Local\Programs\Python\Python39\lib\http\client.py:1285, in HTTPConnection.request(self, method, url, body, headers, encode_chunked)
1284 """Send a complete request to the server."""
-> 1285 self._send_request(method, url, body, headers, encode_chunked)
File ~\AppData\Local\Programs\Python\Python39\lib\http\client.py:1331, in HTTPConnection._send_request(self, method, url, body, headers, encode_chunked)
1330 body = _encode(body, 'body')
-> 1331 self.endheaders(body, encode_chunked=encode_chunked)
File ~\AppData\Local\Programs\Python\Python39\lib\http\client.py:1280, in HTTPConnection.endheaders(self, message_body, encode_chunked)
1279 raise CannotSendHeader()
-> 1280 self._send_output(message_body, encode_chunked=encode_chunked)
File ~\AppData\Local\Programs\Python\Python39\lib\http\client.py:1040, in HTTPConnection._send_output(self, message_body, encode_chunked)
1039 del self._buffer[:]
-> 1040 self.send(msg)
1042 if message_body is not None:
1043
1044 # create a consistent interface to message_body
File ~\AppData\Local\Programs\Python\Python39\lib\http\client.py:980, in HTTPConnection.send(self, data)
979 if self.auto_open:
--> 980 self.connect()
981 else:
File ~\AppData\Local\Programs\Python\Python39\lib\http\client.py:1454, in HTTPSConnection.connect(self)
1452 server_hostname = self.host
-> 1454 self.sock = self._context.wrap_socket(self.sock,
1455 server_hostname=server_hostname)
File ~\AppData\Local\Programs\Python\Python39\lib\ssl.py:500, in SSLContext.wrap_socket(self, sock, server_side, do_handshake_on_connect, suppress_ragged_eofs, server_hostname, session)
494 def wrap_socket(self, sock, server_side=False,
495 do_handshake_on_connect=True,
496 suppress_ragged_eofs=True,
497 server_hostname=None, session=None):
498 # SSLSocket class handles server_hostname encoding before it calls
499 # ctx._wrap_socket()
--> 500 return self.sslsocket_class._create(
501 sock=sock,
502 server_side=server_side,
503 do_handshake_on_connect=do_handshake_on_connect,
504 suppress_ragged_eofs=suppress_ragged_eofs,
505 server_hostname=server_hostname,
506 context=self,
507 session=session
508 )
File ~\AppData\Local\Programs\Python\Python39\lib\ssl.py:1040, in SSLSocket._create(cls, sock, server_side, do_handshake_on_connect, suppress_ragged_eofs, server_hostname, context, session)
1039 raise ValueError("do_handshake_on_connect should not be specified for non-blocking sockets")
-> 1040 self.do_handshake()
1041 except (OSError, ValueError):
File ~\AppData\Local\Programs\Python\Python39\lib\ssl.py:1309, in SSLSocket.do_handshake(self, block)
1308 self.settimeout(None)
-> 1309 self._sslobj.do_handshake()
1310 finally:
SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: certificate has expired (_ssl.c:1129)
During handling of the above exception, another exception occurred:
URLError Traceback (most recent call last)
Cell In[19], line 3
1 from aeon.benchmarking import get_available_estimators, get_estimator_results
----> 3 print(get_available_estimators(task="regression"))
4 results = get_estimator_results(
5 estimators=["DrCIF", "FreshPRINCE"],
6 task="regression",
7 datasets=small_problems,
8 measure="mse",
9 )
10 print(results)
File C:\Code\aeon\aeon\benchmarking\results_loaders.py:240, in get_available_estimators(task, return_dataframe)
233 raise ValueError(
234 f" task {t} is not available on tsc.com, must be one of {VALID_TASK_TYPES}"
235 )
236 path = (
237 f"https://timeseriesclassification.com/results/ReferenceResults/"
238 f"{t}/estimators.txt"
239 )
--> 240 data = pd.read_csv(path)
241 if return_dataframe:
242 return data
File C:\Code\aeon\venv\lib\site-packages\pandas\io\parsers\readers.py:912, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, date_format, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options, dtype_backend)
899 kwds_defaults = _refine_defaults_read(
900 dialect,
901 delimiter,
(...)
908 dtype_backend=dtype_backend,
909 )
910 kwds.update(kwds_defaults)
--> 912 return _read(filepath_or_buffer, kwds)
File C:\Code\aeon\venv\lib\site-packages\pandas\io\parsers\readers.py:577, in _read(filepath_or_buffer, kwds)
574 _validate_names(kwds.get("names", None))
576 # Create the parser.
--> 577 parser = TextFileReader(filepath_or_buffer, **kwds)
579 if chunksize or iterator:
580 return parser
File C:\Code\aeon\venv\lib\site-packages\pandas\io\parsers\readers.py:1407, in TextFileReader.__init__(self, f, engine, **kwds)
1404 self.options["has_index_names"] = kwds["has_index_names"]
1406 self.handles: IOHandles | None = None
-> 1407 self._engine = self._make_engine(f, self.engine)
File C:\Code\aeon\venv\lib\site-packages\pandas\io\parsers\readers.py:1661, in TextFileReader._make_engine(self, f, engine)
1659 if "b" not in mode:
1660 mode += "b"
-> 1661 self.handles = get_handle(
1662 f,
1663 mode,
1664 encoding=self.options.get("encoding", None),
1665 compression=self.options.get("compression", None),
1666 memory_map=self.options.get("memory_map", False),
1667 is_text=is_text,
1668 errors=self.options.get("encoding_errors", "strict"),
1669 storage_options=self.options.get("storage_options", None),
1670 )
1671 assert self.handles is not None
1672 f = self.handles.handle
File C:\Code\aeon\venv\lib\site-packages\pandas\io\common.py:716, in get_handle(path_or_buf, mode, encoding, compression, memory_map, is_text, errors, storage_options)
713 codecs.lookup_error(errors)
715 # open URLs
--> 716 ioargs = _get_filepath_or_buffer(
717 path_or_buf,
718 encoding=encoding,
719 compression=compression,
720 mode=mode,
721 storage_options=storage_options,
722 )
724 handle = ioargs.filepath_or_buffer
725 handles: list[BaseBuffer]
File C:\Code\aeon\venv\lib\site-packages\pandas\io\common.py:368, in _get_filepath_or_buffer(filepath_or_buffer, encoding, compression, mode, storage_options)
366 # assuming storage_options is to be interpreted as headers
367 req_info = urllib.request.Request(filepath_or_buffer, headers=storage_options)
--> 368 with urlopen(req_info) as req:
369 content_encoding = req.headers.get("Content-Encoding", None)
370 if content_encoding == "gzip":
371 # Override compression based on Content-Encoding header
File C:\Code\aeon\venv\lib\site-packages\pandas\io\common.py:270, in urlopen(*args, **kwargs)
264 """
265 Lazy-import wrapper for stdlib urlopen, as that imports a big chunk of
266 the stdlib.
267 """
268 import urllib.request
--> 270 return urllib.request.urlopen(*args, **kwargs)
File ~\AppData\Local\Programs\Python\Python39\lib\urllib\request.py:214, in urlopen(url, data, timeout, cafile, capath, cadefault, context)
212 else:
213 opener = _opener
--> 214 return opener.open(url, data, timeout)
File ~\AppData\Local\Programs\Python\Python39\lib\urllib\request.py:517, in OpenerDirector.open(self, fullurl, data, timeout)
514 req = meth(req)
516 sys.audit('urllib.Request', req.full_url, req.data, req.headers, req.get_method())
--> 517 response = self._open(req, data)
519 # post-process response
520 meth_name = protocol+"_response"
File ~\AppData\Local\Programs\Python\Python39\lib\urllib\request.py:534, in OpenerDirector._open(self, req, data)
531 return result
533 protocol = req.type
--> 534 result = self._call_chain(self.handle_open, protocol, protocol +
535 '_open', req)
536 if result:
537 return result
File ~\AppData\Local\Programs\Python\Python39\lib\urllib\request.py:494, in OpenerDirector._call_chain(self, chain, kind, meth_name, *args)
492 for handler in handlers:
493 func = getattr(handler, meth_name)
--> 494 result = func(*args)
495 if result is not None:
496 return result
File ~\AppData\Local\Programs\Python\Python39\lib\urllib\request.py:1389, in HTTPSHandler.https_open(self, req)
1388 def https_open(self, req):
-> 1389 return self.do_open(http.client.HTTPSConnection, req,
1390 context=self._context, check_hostname=self._check_hostname)
File ~\AppData\Local\Programs\Python\Python39\lib\urllib\request.py:1349, in AbstractHTTPHandler.do_open(self, http_class, req, **http_conn_args)
1346 h.request(req.get_method(), req.selector, req.data, headers,
1347 encode_chunked=req.has_header('Transfer-encoding'))
1348 except OSError as err: # timeout error
-> 1349 raise URLError(err)
1350 r = h.getresponse()
1351 except:
URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: certificate has expired (_ssl.c:1129)>
this is organised as a dictionary of dictionaries. because we cannot be sure all results are present for all datasets.
[ ]:
from aeon.benchmarking import get_estimator_results_as_array
results, names = get_estimator_results_as_array(
estimators=["DrCIF", "FreshPRINCE"],
task="regression",
datasets=small_problems,
measure="mse",
)
print(results)
print(names)
we just need to align our results from the website so they are aligned with the results from our dummy regressor
[20]:
import numpy as np
paired_sorted = sorted(zip(names, results))
names, _ = zip(*paired_sorted)
sorted_rows = [row for _, row in paired_sorted]
sorted_results = np.array(sorted_rows)
print(names)
print(sorted_results)
('CardanoSentiment', 'Covid3Month')
[[0.09821203 0.08379797]
[0.0018498 0.00161534]]
Do the same for our dummy regressor results
[21]:
paired = sorted(zip(small_problems, performance))
small_problems, performance = zip(*paired)
print(small_problems)
print(performance)
all_results = np.column_stack((sorted_results, performance))
print(all_results)
regressors = ["DrCIF", "FreshPRINCE", "Dummy"]
('CardanoSentiment', 'Covid3Month')
(0.09015657223327135, 0.0019998715745554777)
[[0.09821203 0.08379797 0.09015657]
[0.0018498 0.00161534 0.00199987]]
Comparing Regressors¶
aeon provides visualisation tools to compare regressors.
Comparing two regressors¶
We can plot the results against each other. This also presents the wins and losses and some summary statistics.
[22]:
from aeon.visualisation import plot_pairwise_scatter
fig, ax = plot_pairwise_scatter(
all_results[:, 1],
all_results[:, 2],
"FreshPRINCE",
"Dummy",
metric="mse",
lower_better=True,
)
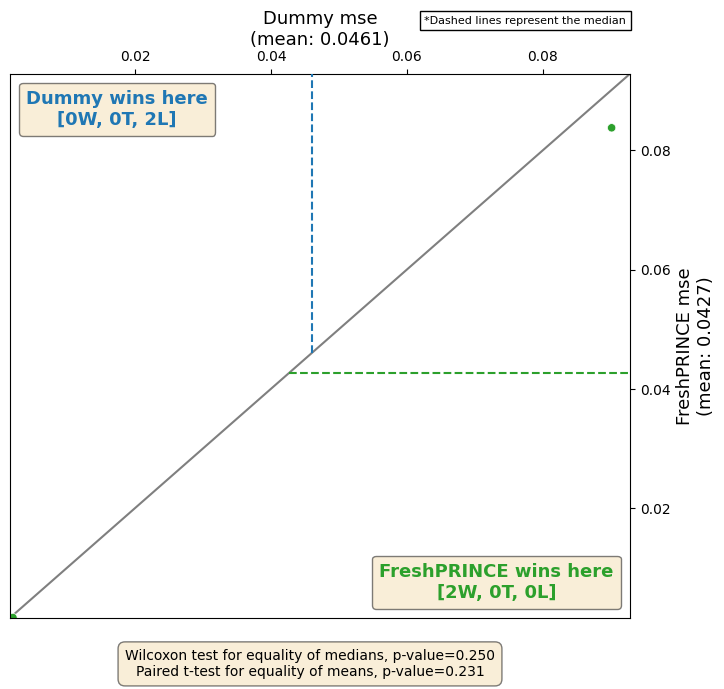
Comparing multiple regressors¶
We can plot the results of multiple regressors on a critical difference diagram, which shows the average rank and groups estimators by whether they are significantly different from each other.
[23]:
from aeon.visualisation import plot_critical_difference
res = plot_critical_difference(
all_results,
regressors,
lower_better=True,
)
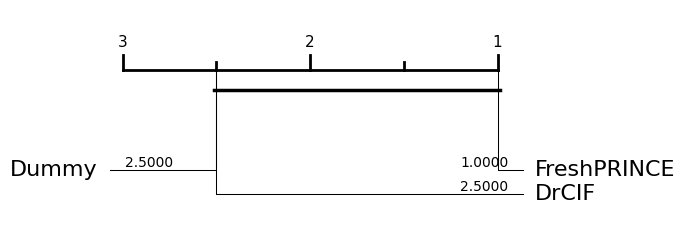
[24]:
from aeon.visualisation import plot_boxplot
res = plot_boxplot(
all_results,
regressors,
relative=True,
)

Generated using nbsphinx. The Jupyter notebook can be found here.