ContractableBOSS¶
- class ContractableBOSS(n_parameter_samples=250, max_ensemble_size=50, max_win_len_prop=1, min_window=10, time_limit_in_minutes=0.0, contract_max_n_parameter_samples=inf, feature_selection='none', n_jobs=1, random_state=None)[source]¶
Bases:
BaseClassifierContractable Bag of Symbolic Fourier Approximation Symbols (cBOSS).
Implementation of BOSS Ensemble from [1] with refinements described in [2].
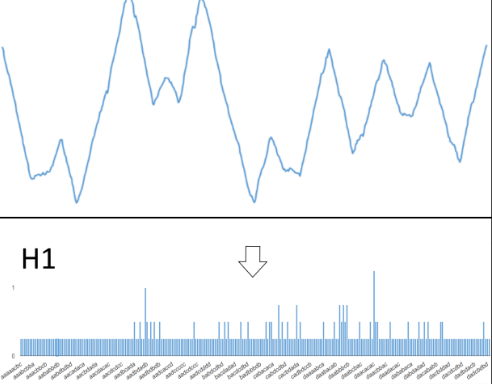
Overview: Input “n” series of length “m” and cBOSS randomly samples n_parameter_samples parameter sets, evaluating each with LOOCV. It then retains max_ensemble_size classifiers with the highest accuracy There are three primary parameters:
alpha: alphabet size
w: window length
l: word length.
For any combination, a single BOSS slides a window length “w” along the series. The “w” length window is shortened to an “l” length word by taking a Fourier transform and keeping the first l/2 complex coefficients. These “l” coefficients are then discretised into “alpha” possible values, to form a word length “l”. A histogram of words for each series is formed and stored.
Fit involves finding “n” histograms.
Predict uses 1 nearest neighbor with a bespoke BOSS distance function.
- Parameters:
- n_parameter_samplesint, default = 250
If search is randomised, number of parameter combos to try.
- max_ensemble_sizeint or None, default = 50
Maximum number of classifiers to retain. Will limit number of retained classifiers even if more than max_ensemble_size are within threshold.
- max_win_len_propint or float, default = 1
Maximum window length as a proportion of the series length.
- min_windowint, default = 10
Minimum window size.
- time_limit_in_minutesint, default = 0
Time contract to limit build time in minutes. Default of 0 means no limit.
- contract_max_n_parameter_samplesint, default=np.inf
Max number of parameter combinations to consider when time_limit_in_minutes is set.
- n_jobsint, default = 1
The number of jobs to run in parallel for both fit and predict.
-1means using all processors.- feature_selectionstr, default = “none”
Sets the feature selections strategy to be used. One of {“chi2”, “none”, “random”}. “chi2” reduces the number of words significantly and is thus much faster (preferred). Random also reduces the number significantly. None applies no feature selection and yields large bag of words, e.g. much memory may be needed.
- random_stateint, RandomState instance or None, default=None
If int, random_state is the seed used by the random number generator; If RandomState instance, random_state is the random number generator; If None, the random number generator is the RandomState instance used by np.random.
- Attributes:
- n_classes_int
Number of classes. Extracted from the data.
- classes_list
The classes labels.
- n_cases_int
Number of instances. Extracted from the data.
- n_timepoints_int
Length of all series (assumed equal).
- estimators_list
List of DecisionTree classifiers.
- n_estimators_int
The final number of classifiers used. Will be <= max_ensemble_size.
- weights_
Weight of each classifier in the ensemble.
- Raises:
- ValueError
Raised when
min_windowis greater thanmax_window + 1. This ensures thatmin_windowdoes not exceedmax_window, preventing invalid window size configurations.
See also
BOSSEnsemble,IndividualBOSSVariants of the BOSS classifier.
Notes
Capabilities ¶ Missing Values
No
Multithreading
Yes
Univariate
Yes
Multivariate
No
Unequal Length
No
Train Estimate
Yes
Contractable
Yes
For the Java version, see TSML.
References
[1]Patrick Schäfer, “The BOSS is concerned with time series classification in the presence of noise”, Data Mining and Knowledge Discovery, 29(6): 2015 https://link.springer.com/article/10.1007/s10618-014-0377-7
[2]Matthew Middlehurst, William Vickers and Anthony Bagnall “Scalable Dictionary Classifiers for Time Series Classification”, in proc 20th International Conference on Intelligent Data Engineering and Automated Learning,LNCS, volume 11871 https://link.springer.com/chapter/10.1007/978-3-030-33607-3_2
Examples
>>> from aeon.classification.dictionary_based import ContractableBOSS >>> from aeon.datasets import load_unit_test >>> X_train, y_train = load_unit_test(split="train") >>> X_test, y_test = load_unit_test(split="test") >>> clf = ContractableBOSS(n_parameter_samples=10, max_ensemble_size=3) >>> clf.fit(X_train, y_train) ContractableBOSS(...) >>> y_pred = clf.predict(X_test)
Methods
clone([random_state])Obtain a clone of the object with the same hyperparameters.
fit(X, y)Fit time series classifier to training data.
fit_predict(X, y, **kwargs)Fits the classifier and predicts class labels for X.
fit_predict_proba(X, y, **kwargs)Fits the classifier and predicts class label probabilities for X.
get_class_tag(tag_name[, raise_error, ...])Get tag value from estimator class (only class tags).
Get class tags from estimator class and all its parent classes.
get_fitted_params([deep])Get fitted parameters.
get_params([deep])Get parameters for this estimator.
get_tag(tag_name[, raise_error, ...])Get tag value from estimator class.
get_tags()Get tags from estimator.
predict(X)Predicts class labels for time series in X.
Predicts class label probabilities for time series in X.
reset([keep])Reset the object to a clean post-init state.
score(X, y[, metric, use_proba, metric_params])Scores predicted labels against ground truth labels on X.
set_params(**params)Set the parameters of this estimator.
set_score_request(*[, metric, ...])Configure whether metadata should be requested to be passed to the
scoremethod.set_tags(**tag_dict)Set dynamic tags to given values.
- clone(random_state=None)[source]¶
Obtain a clone of the object with the same hyperparameters.
A clone is a different object without shared references, in post-init state. This function is equivalent to returning
sklearn.cloneofself. Equal in value totype(self)(**self.get_params(deep=False)).- Parameters:
- random_stateint, RandomState instance, or None, default=None
Sets the random state of the clone. If
None, the random state is not set. Ifint,random_stateis the seed used by the random number generator. IfRandomStateinstance,random_stateis the random number generator.
- Returns:
- estimatorobject
Instance of
type(self), clone of self (see above)
- fit(X, y) BaseCollectionEstimator[source]¶
Fit time series classifier to training data.
- Parameters:
- Xnp.ndarray or list
Input data, any number of channels, equal length series of shape
( n_cases, n_channels, n_timepoints)or 2D np.array (univariate, equal length series) of shape(n_cases, n_timepoints)or list of numpy arrays (any number of channels, unequal length series) of shape[n_cases], 2D np.array(n_channels, n_timepoints_i), wheren_timepoints_iis length of seriesi. Other types are allowed and converted into one of the above.Different estimators have different capabilities to handle different types of input. If
self.get_tag("capability:multivariate")is False, they cannot handle multivariate series, so eithern_channels == 1is true or X is 2D of shape(n_cases, n_timepoints). Ifself.get_tag( "capability:unequal_length")is False, they cannot handle unequal length input. In both situations, aValueErroris raised if X has a characteristic that the estimator does not have the capability for is passed.- ynp.ndarray
1D np.array of float or str, of shape
(n_cases)- class labels (ground truth) for fitting indices corresponding to instance indices in X.
- Returns:
- selfBaseClassifier
Reference to self.
- Raises:
- ValueError
If
Xhas multivariate series but the estimator does not havecapability:multivariatetag set to True.- ValueError
If
Xhas unequal length series but the estimator does not havecapability:unequal_lengthtag set to True.- TypeError
If
yis apd.DataFramewith more than one column.
Notes
Changes state by creating a fitted model that updates attributes ending in “_” and sets is_fitted flag to True.
- fit_predict(X, y, **kwargs) ndarray[source]¶
Fits the classifier and predicts class labels for X.
fit_predict produces prediction estimates using just the train data. By default, this is through 10x cross validation, although some estimators may utilise specialist techniques such as out-of-bag estimates or leave-one-out cross-validation.
Classifiers which override _fit_predict will have the
capability:train_estimatetag set to True.Generally, this will not be the same as fitting on the whole train data then making train predictions. To do this, you should call fit(X,y).predict(X)
- Parameters:
- Xnp.ndarray or list
Input data, any number of channels, equal length series of shape
( n_cases, n_channels, n_timepoints)or 2D np.array (univariate, equal length series) of shape(n_cases, n_timepoints)or list of numpy arrays (any number of channels, unequal length series) of shape[n_cases], 2D np.array(n_channels, n_timepoints_i), wheren_timepoints_iis length of seriesi. other types are allowed and converted into one of the above.Different estimators have different capabilities to handle different types of input. If
self.get_tag("capability:multivariate")is False, they cannot handle multivariate series, so eithern_channels == 1is true or X is 2D of shape(n_cases, n_timepoints). Ifself.get_tag( "capability:unequal_length")is False, they cannot handle unequal length input. In both situations, aValueErroris raised if X has a characteristic that the estimator does not have the capability for is passed.- ynp.ndarray
1D np.array of float or str, of shape
(n_cases)- class labels (ground truth) for fitting indices corresponding to instance indices in X.- kwargsdict
key word arguments to configure the default cross validation if the base class default fit_predict is used (i.e. if function
_fit_predictis not overridden. If_fit_predictis overridden, kwargs may not function as expected. If_fit_predictis not overridden, valid input iscv_sizeinteger, which is the number of cross validation folds to use to estimate train data. Ifcv_sizeis not passed, the default is 10. Ifcv_sizeis greater than the minimum number of samples in any class, it is set to this minimum.
- Returns:
- predictionsnp.ndarray
shape
[n_cases]- predicted class labels indices correspond to instance indices in
- Raises:
- ValueError
If
Xhas multivariate series but the estimator does not havecapability:multivariatetag set to True.- ValueError
If
Xhas unequal length series but the estimator does not havecapability:unequal_lengthtag set to True.- ValueError
If
cv_sizeis not an integer greater than 0.- ValueError
If all classes have fewer than 2 samples, making cross-validation impossible.
- fit_predict_proba(X, y, **kwargs) ndarray[source]¶
Fits the classifier and predicts class label probabilities for X.
fit_predict_proba produces probability estimates using just the train data. By default, this is through 10x cross validation, although some estimators may utilise specialist techniques such as out-of-bag estimates or leave-one-out cross-validation.
Classifiers which override _fit_predict_proba will have the
capability:train_estimatetag set to True.Generally, this will not be the same as fitting on the whole train data then making train predictions. To do this, you should call fit(X,y).predict_proba(X)
- Parameters:
- Xnp.ndarray or list
Input data, any number of channels, equal length series of shape
( n_cases, n_channels, n_timepoints)or 2D np.array (univariate, equal length series) of shape(n_cases, n_timepoints)or list of numpy arrays (any number of channels, unequal length series) of shape[n_cases], 2D np.array(n_channels, n_timepoints_i), wheren_timepoints_iis length of seriesi. other types are allowed and converted into one of the above.Different estimators have different capabilities to handle different types of input. If
self.get_tag("capability:multivariate")is False, they cannot handle multivariate series, so eithern_channels == 1is true or X is 2D of shape(n_cases, n_timepoints). Ifself.get_tag( "capability:unequal_length")is False, they cannot handle unequal length input. In both situations, aValueErroris raised if X has a characteristic that the estimator does not have the capability for is passed.- ynp.ndarray
1D np.array of float or str, of shape
(n_cases)- class labels (ground truth) for fitting indices corresponding to instance indices in X.- kwargsdict
key word arguments to configure the default cross validation if the base class default fit_predict is used (i.e. if function
_fit_predictis not overridden. If_fit_predictis overridden, kwargs may not function as expected. If_fit_predictis not overridden, valid input iscv_sizeinteger, which is the number of cross validation folds to use to estimate train data. Ifcv_sizeis not passed, the default is 10. Ifcv_sizeis greater than the minimum number of samples in any class, it is set to this minimum.
- Returns:
- probabilitiesnp.ndarray
2D array of shape
(n_cases, n_classes)- predicted class probabilities First dimension indices correspond to instance indices in X, second dimension indices correspond to class labels, (i, j)-th entry is estimated probability that i-th instance is of class j
- Raises:
- ValueError
If
Xhas multivariate series but the estimator does not havecapability:multivariatetag set to True.- ValueError
If
Xhas unequal length series but the estimator does not havecapability:unequal_lengthtag set to True.- ValueError
If
cv_sizeis not an integer greater than 0.- ValueError
If all classes have fewer than 2 samples, making cross-validation impossible.
- classmethod get_class_tag(tag_name, raise_error=True, tag_value_default=None)[source]¶
Get tag value from estimator class (only class tags).
- Parameters:
- tag_namestr
Name of tag value.
- raise_errorbool, default=True
Whether a
ValueErroris raised when the tag is not found.- tag_value_defaultany type, default=None
Default/fallback value if tag is not found and error is not raised.
- Returns:
- tag_value
Value of the
tag_nametag in cls. If not found, returns an error ifraise_errorisTrue, otherwise it returnstag_value_default.
- Raises:
- ValueError
if
raise_errorisTrueandtag_nameis not inself.get_tags().keys()
Examples
>>> from aeon.classification import DummyClassifier >>> DummyClassifier.get_class_tag("capability:multivariate") True
- classmethod get_class_tags()[source]¶
Get class tags from estimator class and all its parent classes.
- Returns:
- collected_tagsdict
Dictionary of tag name and tag value pairs. Collected from
_tagsclass attribute via nested inheritance. These are not overridden by dynamic tags set byset_tagsor class__init__calls.
- get_fitted_params(deep=True)[source]¶
Get fitted parameters.
- State required:
Requires state to be “fitted”.
- Parameters:
- deepbool, default=True
If
True, will return the fitted parameters for this estimator and contained subobjects that are estimators.
- Returns:
- fitted_paramsdict
Fitted parameter names mapped to their values.
- get_params(deep=True)¶
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- get_tag(tag_name, raise_error=True, tag_value_default=None)[source]¶
Get tag value from estimator class.
Includes dynamic and overridden tags.
- Parameters:
- tag_namestr
Name of tag to be retrieved.
- raise_errorbool, default=True
Whether a
ValueErroris raised when the tag is not found.- tag_value_defaultany type, default=None
Default/fallback value if tag is not found and error is not raised.
- Returns:
- tag_value
Value of the
tag_nametag in self. If not found, returns an error ifraise_errorisTrue, otherwise it returnstag_value_default.
- Raises:
- ValueError
if raise_error is
Trueandtag_nameis not inself.get_tags().keys()
Examples
>>> from aeon.classification import DummyClassifier >>> d = DummyClassifier() >>> d.get_tag("capability:multivariate") True
- get_tags()[source]¶
Get tags from estimator.
Includes dynamic and overridden tags.
- Returns:
- collected_tagsdict
Dictionary of tag name and tag value pairs. Collected from
_tagsclass attribute via nested inheritance and then any overridden and new tags from__init__orset_tags.
- predict(X) ndarray[source]¶
Predicts class labels for time series in X.
- Parameters:
- Xnp.ndarray or list
Input data, any number of channels, equal length series of shape
( n_cases, n_channels, n_timepoints)or 2D np.array (univariate, equal length series) of shape(n_cases, n_timepoints)or list of numpy arrays (any number of channels, unequal length series) of shape[n_cases], 2D np.array(n_channels, n_timepoints_i), wheren_timepoints_iis length of seriesiother types are allowed and converted into one of the above.Different estimators have different capabilities to handle different types of input. If
self.get_tag("capability:multivariate")is False, they cannot handle multivariate series, so eithern_channels == 1is true or X is 2D of shape(n_cases, n_timepoints). Ifself.get_tag( "capability:unequal_length")is False, they cannot handle unequal length input. In both situations, aValueErroris raised if X has a characteristic that the estimator does not have the capability for is passed.
- Returns:
- predictionsnp.ndarray
1D np.array of float, of shape (n_cases) - predicted class labels indices correspond to instance indices in X
- Raises:
- ValueError
If
Xhas multivariate series but the estimator does not havecapability:multivariatetag set to True.- ValueError
If
Xhas unequal length series but the estimator does not havecapability:unequal_lengthtag set to True.- ValueError
If the time series length of
Xdoes not match the length seen during fit.- ValueError
If the number of channels in
Xdoes not match the number of channels seen during fit (for multivariate estimators).- NotFittedError
If the classifier has not been fitted yet (
fitnot called).
- predict_proba(X) ndarray[source]¶
Predicts class label probabilities for time series in X.
- Parameters:
- Xnp.ndarray or list
Input data, any number of channels, equal length series of shape
( n_cases, n_channels, n_timepoints)or 2D np.array (univariate, equal length series) of shape(n_cases, n_timepoints)or list of numpy arrays (any number of channels, unequal length series) of shape[n_cases], 2D np.array(n_channels, n_timepoints_i), wheren_timepoints_iis length of seriesi. other types are allowed and converted into one of the above.Different estimators have different capabilities to handle different types of input. If
self.get_tag("capability:multivariate")is False, they cannot handle multivariate series, so eithern_channels == 1is true or X is 2D of shape(n_cases, n_timepoints). Ifself.get_tag( "capability:unequal_length")is False, they cannot handle unequal length input. In both situations, aValueErroris raised if X has a characteristic that the estimator does not have the capability for is passed.
- Returns:
- probabilitiesnp.ndarray
2D array of shape
(n_cases, n_classes)- predicted class probabilities First dimension indices correspond to instance indices in X, second dimension indices correspond to class labels, (i, j)-th entry is estimated probability that i-th instance is of class j
- Raises:
- ValueError
If
Xhas multivariate series but the estimator does not havecapability:multivariatetag set to True.- ValueError
If
Xhas unequal length series but the estimator does not havecapability:unequal_lengthtag set to True.- ValueError
If the time series length of
Xdoes not match the length seen during fit.- ValueError
If the number of channels in
Xdoes not match the number of channels seen during fit (for multivariate estimators).- NotFittedError
If the classifier has not been fitted yet (
fitnot called).
- reset(keep=None)[source]¶
Reset the object to a clean post-init state.
After a
self.reset()call,selfis equal or similar in value totype(self)(**self.get_params(deep=False)), assuming no other attributes were kept usingkeep.- Detailed behaviour:
- removes any object attributes, except:
hyper-parameters (arguments of
__init__) object attributes containing double-underscores, i.e., the string “__”
runs
__init__with current values of hyperparameters (result ofget_params)- Not affected by the reset are:
object attributes containing double-underscores class and object methods, class attributes any attributes specified in the
keepargument
- Parameters:
- keepNone, str, or list of str, default=None
If
None, all attributes are removed except hyperparameters. Ifstr, only the attribute with this name is kept. Iflistofstr, only the attributes with these names are kept.
- Returns:
- selfobject
Reference to self.
- Raises:
- TypeError
If ‘keep’ is not a string or a list of strings.
- score(X, y, metric='accuracy', use_proba=False, metric_params=None) float[source]¶
Scores predicted labels against ground truth labels on X.
- Parameters:
- Xnp.ndarray or list
Input data, any number of channels, equal length series of shape
( n_cases, n_channels, n_timepoints)or 2D np.array (univariate, equal length series) of shape(n_cases, n_timepoints)or list of numpy arrays (any number of channels, unequal length series) of shape[n_cases], 2D np.array(n_channels, n_timepoints_i), wheren_timepoints_iis length of seriesi. other types are allowed and converted into one of the above.Different estimators have different capabilities to handle different types of input. If
self.get_tag("capability:multivariate")is False, they cannot handle multivariate series, so eithern_channels == 1is true or X is 2D of shape(n_cases, n_timepoints). Ifself.get_tag( "capability:unequal_length")is False, they cannot handle unequal length input. In both situations, aValueErroris raised if X has a characteristic that the estimator does not have the capability for is passed.- ynp.ndarray
1D np.array of float or str, of shape
(n_cases)- class labels (ground truth) for fitting indices corresponding to instance indices in X.- metricUnion[str, callable], default=”accuracy”,
Defines the scoring metric to test the fit of the model. For supported strings arguments, check sklearn.metrics.get_scorer_names.
- use_probabool, default=False,
Argument to check if scorer works on probability estimates or not.
- metric_paramsdict, default=None,
Contains parameters to be passed to the scoring function. If None, no parameters are passed.
- Returns:
- scorefloat
Accuracy score of predict(X) vs y.
- Raises:
- ValueError
If
metricis a string not found insklearn.metrics.get_scorer_names().- ValueError
If
metricis not a string or callable.- NotFittedError
If the classifier has not been fitted yet (
fitnot called).
- set_params(**params)¶
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.
- set_score_request(*, metric: bool | None | str = '$UNCHANGED$', metric_params: bool | None | str = '$UNCHANGED$', use_proba: bool | None | str = '$UNCHANGED$') ContractableBOSS¶
Configure whether metadata should be requested to be passed to the
scoremethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
- metricstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
metricparameter inscore.- metric_paramsstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
metric_paramsparameter inscore.- use_probastr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
use_probaparameter inscore.
- Returns:
- selfobject
The updated object.